
How Abstraction Could Have Saved Our Million-Dollar Software

Hossein Bakhtiari
—Apr 30, 2025

Over the past decade, I’ve worked on software systems that were elegant, efficient—and eventually, impossible to maintain. Not because the code was bad, but because we coupled ourselves too tightly to technologies that didn’t last. In this post, I’ll share hard-earned lessons from real-world .NET projects: how WinForms, WCF, and even Silverlight projects were set up for failure simply because we didn’t design for change. Along the way, I’ll unpack what Abstractionand Dependency Inversion really mean, and why they are the keys to writing software that can outlive any framework, database, or library.
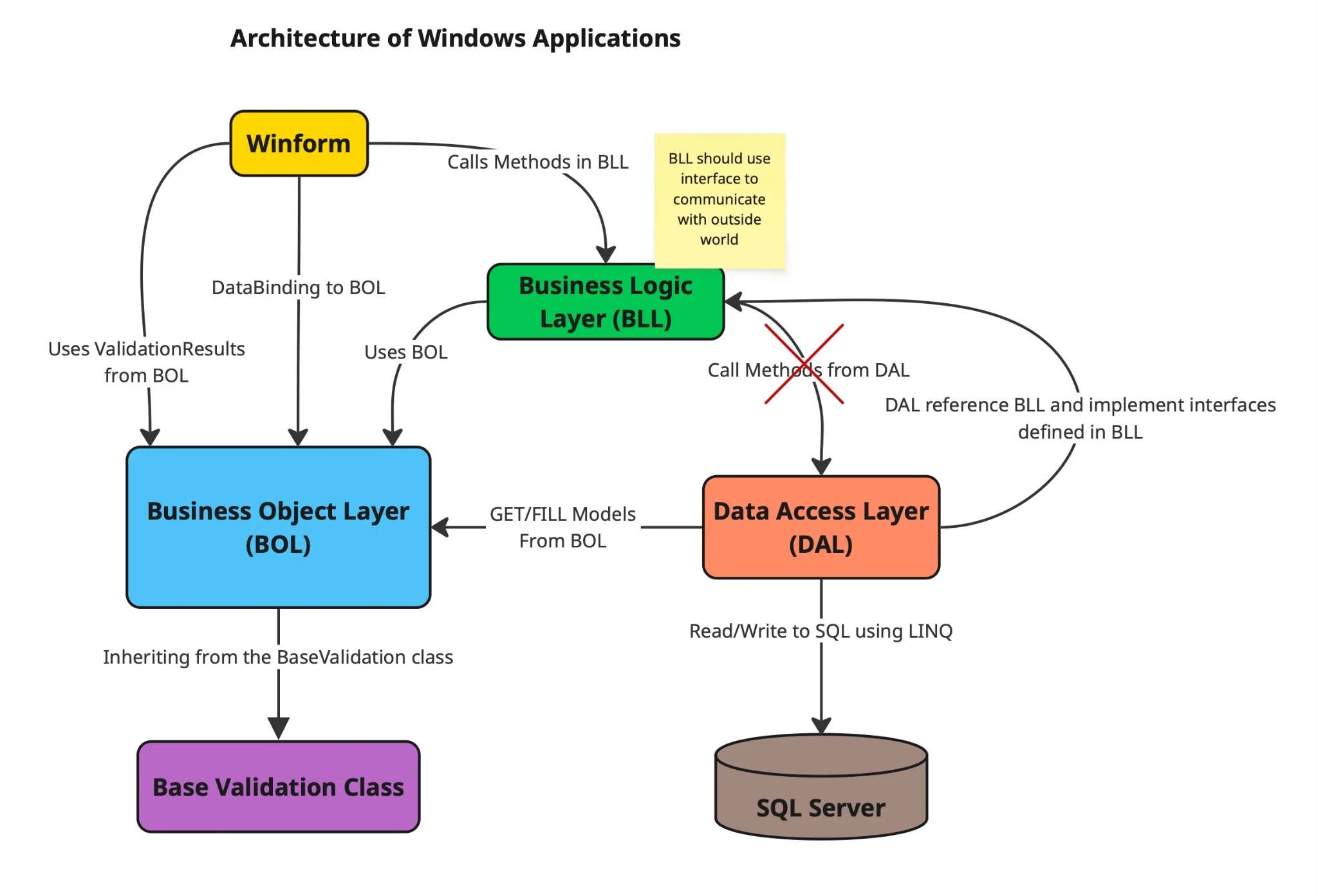
Back in 2012, I worked on a suite of Windows applications that I was genuinely proud of. These were solid, well-structured systems that made customers happy and solved real problems efficiently. We were using a clean Layered Architecture:
- WinForms Layer: bound directly to Model objects.
- Business Layer: received those models, performed business logic, and handled validation.
- Data Access Layer (DAL): used LINQ to SQL to persist data in a relational database.
What made these applications stand out—even for their time—was the clarity of the separation between layers. The WinForms UI never directly talked to the database. Instead, it passed data to the Business Layer, which in turn delegated to the DAL. Our business validations were implemented using a base validation class, and each model inherited from it—structured much like FluentValidation today.
It was pragmatic, elegant, and powerful. The architecture made sense. The code was clean. I enjoyed working with it, and I was proud of what we were building.
But the tech landscape was shifting fast.
Web applications were quickly rising. WinForms was beginning to fade. Users wanted browser-based interfaces, and later, mobile. And while our apps were beautiful for their time, the very thing that made them great—their tightly bound, layered architecture—became their greatest weakness.
Here’s what our architecture looked like back then:

Understanding the Diagram
The WinForms Layer interacted primarily with BOL (Business Object Layer) using a technique that's very familiar to modern frontend developers: data binding. Just like frameworks such as Angular or React use two-way binding to keep the UI and model in sync, our WinForms applications did the same.
Rather than writing manual code like:
NameTextBox.Text = employee.Name;
employee.Name = NameTextBox.Text;we leveraged WinForms' powerful binding engine, which automatically synchronized model properties with UI controls.
Tip for WinForms developers: Visual Studio actually supports this natively—if you drag a property from the Data Sources panel onto your form, it wires up the binding for you automatically. This includes both display and validation logic.
Seamless Validation Integration
The Model Layer (BOL) didn’t just store data—it also carried validation logic. Each model inherited from a BaseValidation class, allowing the UI to bind directly to validation results. This kept the UI logic clean while still giving end users instant feedback.
Clear Separation of Concerns
When the user submitted a form, the WinForms Layer called the appropriate method in the Business Logic Layer (BLL), passing in the populated BOL object. The BLL then handled all business rules and interactions with the Data Access Layer (DAL).
This meant:
- The UI didn’t contain any business logic.
- The UI wasn’t tightly coupled to database logic.
- And the system was both clean and testable—a big win for long-term maintainability.
What We Got Right — and What We Didn’t See Coming
One thing we absolutely got right in that project was keeping the business logic out of the WinForms layer. That separation gave us clarity, structure, and testability. We were also cautious and pragmatic about third-party libraries — in fact, we avoided them altogether because we couldn’t guarantee how long they’d last or whether they’d remain maintained.
But what we didn’t see coming was Microsoft’s evolution of the ecosystem.
- We didn’t expect .NET Core and .NET Standard to fundamentally reshape the platform.
- We didn’t realize that LINQ to SQL — something we had fully adopted — would soon be deprecated.
- We didn’t yet understand how the web was about to dominate, or that a well-designed business layer could be reused across WinForms, Web, and even mobile.
- And above all, we didn’t fully grasp the long-term consequences of designing systems around the infrastructure we had at the time.
Looking back, I still genuinely loved working on those applications. They were robust, clean, and meaningful. But if there’s one lesson I’ve learned since then, it’s this:
We should have abstracted the things that change and depended on the things that don't.
And that’s exactly what Abstraction and the Dependency Inversion Principle are about.
Now, I want to be clear: I'm not trying to say that infrastructure is unimportant or that cloud platforms don’t matter. On the contrary — a great application absolutely needs a solid infrastructure setup to meet real-world demands.
But infrastructure is not where your business logic should live.
A well-architected application should have a business layer that can be tested, verified, and reasoned about independently — without needing the database, the cloud, the filesystem, or any network dependency running. That’s what abstraction enables: the freedom to evolve your infrastructure without rewriting your core logic.
And that’s how we could have saved those legacy applications from obsolescence — not by predicting the future, but by preparing for change.
What Does Abstraction Really Mean in This Context?
Abstraction can mean many things in software development, but in the context of application architecture — especially in our WinForms example — it's about one powerful idea:
Don’t depend directly on infrastructure. Depend on contracts.
In our case, the infrastructure was the database — and in the original design, the DAL was tightly coupled to LINQ to SQL. Every business operation went straight to a specific data source. That worked fine… until it didn’t.
The right way to abstract this would have been to define an interface that hides how the data is retrieved or persisted. Then the business layer could depend on that interface — and not on LINQ, SQL Server, or any other specific tech.
With that abstraction in place, you could plug in:
- A relational database (like SQL Server or PostgreSQL)
- A document database (like MongoDB)
- An in-memory database (great for unit tests)
- A remote API (to pull the data from another system)
- An event stream (to replay a timeline of domain events)
The business logic would work exactly the same regardless.
This is the power of abstraction: You don’t design for the database, or for the cloud, or for your current tech stack. You design for the business needs — and abstract away the details that are likely to change.
Let's Look at an Example of Abstraction in Action
To make this concrete, let’s walk through a small example. Imagine we’re working with a simple EmployeeService class that handles employee promotions.
The business rule is straightforward:
If the employee exists and is not terminated, we promote them by increasing their level and saving the updated record.
We’ll first examine what this looks like without abstraction, using a direct dependency on a data access class. Then we’ll refactor it to use an interface, showing how abstraction improves flexibility and testability.
🚫 Bad Design: Direct Dependency on the Data Layer
public class EmployeeService
{
public bool PromoteEmployee(int employeeId)
{
var employee = new DbEmployee().GetById(employeeId); // direct dependency
if (employee == null || employee.IsTerminated)
return false;
employee.Level += 1;
new DbEmployee().Update(employee); // direct dependency again
return true;
}
}In this version, EmployeeService is tightly coupled to the concrete class DbEmployee, which represents the data access layer (DAL). This might seem fine in the beginning, but this design introduces several problems:
- You can’t test PromoteEmployee without setting up a real database.
- You’re locked into whatever infrastructure DbEmployee uses — LINQ to SQL, EF, SQL Server, etc.
- If you later decide to fetch employees from an API or store them in a NoSQL database, you’ll have to rewrite this class.
✅ Good Design: Depend on an Interface
Now, let’s refactor the code by introducing an abstraction.
public interface IEmployeeRepository
{
Employee GetById(int id);
void Update(Employee employee);
}We define an interface that describes the operations needed by the business layer. Now we implement this interface in a class that interacts with the infrastructure (e.g., SQL Server, EF Core, API, etc.):
public class SqlEmployeeRepository : IEmployeeRepository
{
public Employee GetById(int id)
{
// Real database logic here
return new Employee(); // placeholder
}
public void Update(Employee employee)
{
// Save changes to the database
}
}And here’s the updated business logic:
public class EmployeeService
{
private readonly IEmployeeRepository _repository;
public EmployeeService(IEmployeeRepository repository)
{
_repository = repository;
}
public bool PromoteEmployee(int employeeId)
{
var employee = _repository.GetById(employeeId);
if (employee == null || employee.IsTerminated)
return false;
employee.Level += 1;
_repository.Update(employee);
return true;
}
}Now EmployeeService doesn't care where the employee data comes from or how it's stored. It only knows what it needs: an employee object and a way to persist changes.
You can plug in any implementation of IEmployeeRepository:
- A real database
- An in-memory store for tests
- A REST API
- An event stream
- A mock in your test suite
This is abstraction in practice. And when paired with Dependency Injection, you get loose coupling, flexibility, and testability — the very things our legacy WinForms applications were missing.
What Does Dependency Inversion Really Mean?
The Dependency Inversion Principle — the "D" in SOLID — says:
High-level modules should not depend on low-level modules. Both should depend on abstractions.
Let’s be honest: on first read, this sounds a bit too abstract and theoretical. So let’s break it down in the context of the architecture we’ve been discussing.
Applying It to Our Architecture
If you scroll back to the original architecture diagram, you’ll see that the Business Logic Layer (BLL) directly depends on the Data Access Layer (DAL).
That’s exactly what this principle warns us against.
According to the Dependency Inversion Principle:
- The Business Layer (high-level module) should not reference or know about the DAL (low-level module).
- Instead, both the Business Layer and DAL should depend on a shared abstraction — typically an interface.
In our earlier code example, that abstraction was the IEmployeeRepository.
How This Looks in Practice
Instead of the Business Layer calling DbEmployee or SqlEmployeeRepository directly, it should work with an interface like IEmployeeRepository.
Then, the DAL (infrastructure) implements this interface and becomes swappable at runtime — without the business logic knowing or caring about the specific implementation.
In Clean Architecture, it's also common to define the interface inside the Business Layer itself, which leads to something powerful:
The infrastructure layer (DAL) now depends on the business, not the other way around.
So, instead of this:

You end up with this:

The DAL implements the interface. The BLL consumes the interface. And the code becomes loosely coupled, testable, and future-proof.
Visualizing the Inversion
The diagram below illustrates the problem with the original WinForms architecture and how correcting the direction of dependencies creates a more maintainable design.
A Small Change, A Massive Impact
This might look like a small change — just an interface between layers — but it’s a game changer. Without it, writing automated tests becomes painful or even impossible. If we had been practicing Test-Driven Development (TDD) back then, this tight coupling between the Business Layer and the DAL would’ve surfaced as a major problem immediately.
TDD wasn’t new at the time either. It was popularized in the early 2000s, largely thanks to Kent Beck and Extreme Programming (XP). His book Test-Driven Development: By Example was published in 2002 and quickly became a cornerstone of agile software practices.
Even during the .NET Framework days in 2012, we had solid tools to write unit tests:
- MSTest, the built-in framework from Microsoft
- NUnit, a widely adopted alternative with strong community support
If we had followed TDD, our architecture would have naturally evolved to depend on abstractions, because testing a tightly coupled class like EmployeeService (with hardcoded DbEmployee calls) would have been a nightmare.
TDD doesn’t just lead to more tests — it forces better design.
Not Just a WinForms Tragedy
You might think this kind of architectural failure — tightly coupling business logic to UI or infrastructure — only happened with Windows applications when the web became dominant. But that’s not true.
Years later, I joined another million-dollar C# project. This time, the UI was built using Silverlight, and the backend used WCF (Windows Communication Foundation). Around that time, Angular 2 and .NET Core had just been released.
Then came the bad news: Silverlight was deprecated. WCF was falling out of favor, as REST APIs became the standard.
The company decided to modernize: replace Silverlight with Angular and WCF with .NET Core Web APIs. Sounds like a solid plan, right?
But we couldn't migrate the project — we had to rewrite it from scratch.
Why?
- The application was tightly coupled to WCF
- It used Hibernate (NHibernate) for database access, deeply integrated
- Worst of all, some business logic was buried inside Silverlight UI code
Today, I know that was the wrong call. If you ever face this kind of situation, don’t rush to rewrite. Instead, work gradually on the legacy code: isolate dependencies, introduce abstractions, write tests. Over time, you can decouple enough to swap deprecated pieces safely.
The Classic Rewrite Trap
This was a textbook scenario: One team maintained the legacy system, fixing bugs and releasing features. Another team built the “greenfield” replacement, iterating quickly and making bold promises.
Anyone who’s lived through this knows how painful it is:
- The old system must still serve users and evolve
- The new system is under pressure to catch up — fast
- Teams feel split, overstretched, and frustrated
Initially, greenfield work feels fun and productive. Morale is high. But without addressing the underlying design flaws, the new system often repeats the same mistakes. And before long, it ends up in the same mess — just with newer tech.
Migrating to modern tools isn’t enough. If you don’t embrace abstraction and loose coupling, history will repeat itself.
Final Thoughts: Future-Proofing Through Abstraction
The stories I shared — from WinForms to Silverlight — are not just tales of outdated technology. They’re cautionary lessons about what happens when systems are built without proper abstraction and dependency inversion.
Even today, I still see these mistakes repeated in many projects.
If you’re injecting DbContext from Entity Framework directly into your services, you’re repeating the same coupling mistake — and I promise, one day there will be a replacement for that. When that day comes, your system will be just as hard to migrate as the ones I’ve described.
If you're using open-source libraries like FluentValidation, MediatR, or FluentAssertions — or even paid tools — I urge you to think twice. These aren’t bad libraries; in fact, they’re incredibly useful. But the issue isn’t about quality — it's about control.
The moment your business logic depends directly on something outside your control, you’ve introduced risk.
Library maintainers have motivations and momentum today, but that might not be the case tomorrow. If you want to use them — or can’t convince your team not to — the best approach is to use them indirectly: define your own interfaces or abstractions and treat the library as a swappable implementation detail.
Here’s the strange thing: Developers often define “legacy code” as any code that runs on old technology. But that’s not the real problem.
The true definition of legacy code is: code that lacks automated tests.
Technology will keep evolving. Your language, your framework, your infrastructure — these will all change.
But if you’re writing C#, your mindset should be this: “As long as C# exists, my application should be able to live, grow, and adapt.”
That’s the power of abstraction. That’s how you future-proof your software.